Restitution ateliers Self Data Territorial - La feuille de Route
Introduction :
Les enjeux du Self Data Territorial
Après plus de sept années passées à explorer le concept Self Data à travers le projet MesInfos et ses différentes « saisons » d’exploration et d’expérimentations, la Fing a fait le pari des Self Data Territorial et s’est associée à trois villes (La Rochelle, Lyon, Nantes) pour en dessiner les contours.
En raison de leur position unique, les collectivités territoriales ont un peuvent prendre un rôle moteur dans le développement du Self Data au bénéfice de leurs citoyens et du territoire :
- En tant que contrôleurs de données : montrer l’exemple développer ou déployer leurs propres plateformes et applications ; exiger de leurs fournisseurs et autres partenaires de jouer le jeu…
- Comme acteurs du soutien à l’innovation : soutenir des projets compatibles Self Data ; créer un cadre de confiance, faciliter les coopérations entre les acteurs et les expérimentations…
- Comme organisations démocratiques poursuivant l’intérêt général : donner aux citoyens le pouvoir de décider de ce qu’ils font de leurs données, co-concevoir des scénarios d’usage des données personnelles, faciliter les médiations numériques…
Si en 2019, l’heure était à la construction du Kit Self Data Territorial pour permettre à chaque ville qui le souhaite d’expérimenter, en 2020/21, la Fing s’attèlera à produire une « feuille de route » des villes européennes pour l’implémentation du Self Data Territorial à une plus large échelle.
Cette démarche s’appuiera notamment sur des analyses SWOT des villes/territoires et de leurs partenaires locaux.
La participation à l’élaboration de la feuille de route Self Data permet aux villes/territoires de :
- Poser un diagnostic de leurs capacités/politiques en matière de collecte et gestion des données personnelles (techniques, financières, humaines), et de la mise en oeuvre de projets Self Data,
- Nouer des alliances avec d’autres villes/territoires autour de projets Self Data,
- Être accompagné(e)s dans leurs réflexions autour de leurs stratégies Self Data.
La participation à l’élaboration de la feuille de route Self Data permet aux organisations (grands groupes, startups…) de :
- Mieux connaitre le paysage/écosystème local potentiellement embarqué dans des projets Self Data,
- Se projeter dans la perspective d’accompagner les villes et les territoires en tant que partenaire dans des projets Self Data,
- Explorer des pistes d’innovation et des opportunités de marché grâce au Self Data
Des ateliers SWOT ont été menés entre 2020 et 2021, en voici une synthèse des résultats :
Tableau synthétique des résultats ateliers SWOT
| CATÉGORIES | SOUS-CATÉGORIES | ÉLÉMENTS | NBR | |
|---|---|---|---|---|
| FORCES | Détenteur de données | Les villes détiennent une grande quantité de données variée/multiples. | 1 | |
| FORCES | Connaissance/expertise | Les agents de la ville ont l’habitude d’utiliser des logiciels informatiques/dans certains cas cela s’étend jusqu’à la connaissance du Self Data. | 1 | |
| FORCES | Légitimité/confiance | Cela peut être compris de deux manières : institution ayant la confiance des citoyens ou institution souhaitant mieux connaître/mieux dialoguer avec les citoyens. | 1 | |
| FORCES | Mobiliser/fédérer | Institution en mesure de mobiliser différentes parties prenantes et des les fédérer autour d’un même projet. | 1 | |
| FAIBLESSES | Manque de structure/qualité | Les données sont silotées, fragmentées, peu structurées, peu organisées. | 1 | |
| FAIBLESSES | Niveau d'expertise disparate | Les villes ne sont pas toutes au même niveau de maturité concernant les DP/SD, bcp d’agents et d’élus restent peu au fait. | 1 | |
| FAIBLESSES | Manque de confiance/légitimité | Peu de la défiance des citoyens qui ne souhaitent pas que l’on touche à leurs DP/des doutes sur la légitimité d’une ville à intervenir sur un projet qui ne concerne pas uniquement les politiques publiques. | 1 | |
| FAIBLESSES | Divergence d'intérêts | Les villes ne partagent pas toutes les mêmes visions/objectifs et ne travaillent pas assez ensemble. | 1 | |
| OPPORTUNITES | Innovation | L’occasion pour les villes de construire/offrir des plus innovants/simples/éthiques, d’évaluer les politiques publiques et de participer au développement du territoire. | 1 | |
| OPPORTUNITES | Environnement propice | Réglementations en vigueur, expérimentations en cours, portage politique dans certaine ville, DG connect impliquée sur MyData. | 1 | |
| OPPORTUNITES | Co-construction | Forte volonté des villes d’impliquer les citoyens sur un tel projet et désire des citoyens de s’impliquer davantage, possibilité de co-construire avec d’autres villes et de mutualiser les efforts. | 1 | |
| MENACES | Poids des GAFAM | Sont déjà présents aux niveau des villes (éducation, mobilité, santé..) et comptent bien renforcer leurs positions et pourraient freiner des initiatives comme le SD. | 1 | |
| MENACES | Difficultés techniques | Complexité des services, impossibilité d'anonymiser, manque d’interopérabilité/API, risques d’attaques. | 1 | |
| MENACES | Environnement non-favorable | N’est pas la priorité, n’obtient pas l’adhésion politique, impact environnemental de la duplication des données, modèles économiques peu viables, méfiance de la part des citoyens. | 1 | |
| MENACES | Self Data Washing | Que cela ne reste qu’un projet de “geek” + qui aggraverait la fracture numérique. | 1 |
Suite aux analyse SWOT, des actions (en lien) ont été identifiées pour permettre l’implémentation du Self Data Territorial :

COMMENT PARTAGER LES DONNÉES PERSONNELLES ?
CINQ MODÈLES DE GOUVERNANCE POUR LE SELF DATA
Lors de nos travaux au sein de MesInfos, nous avons particulièrement observé et expérimenté un type de modèle du partage : celui du cloud personnel. Mais si il présente de nombreux avantages, il n’existe pas un seul et unique modèle permettant de rendre les individus maîtres réutilisateurs de leurs données. Nous avons compté au moins cinq modèles “sur étagère”, qui peuvent être hybridés, modifiés, etc. S’il n’existe pas une seule façon de faire du Self Data, le rôle de l’acteur public local, en tant que chef de file du mouvement, sera d’orienter les choix vers tel ou tel modèle de gouvernance de la donnée personnelle partagée.
Les modèles de gouvernance que nous décrivons ici ne se positionnent pas sur le même niveau. Les deux premiers sont des modèles techniques très différents du partage (transfert direct, cloud personnel), ce qui n’implique bien sûr en aucun cas qu’ils soient neutres, tout dépend de leur implémentation, de qui les porte, etc. Les trois derniers modèles (plateforme tiers de confiance, coopérative de données, régie/civic data trust) sont plutôt des modes d’organisation et peuvent d’ailleurs exister avec les deux premiers. En détaillant ici les différentes façon de “faire du Self Data”, nous espérons inspirer les territoires et les outiller dans leurs choix.
Le cloud personnel
[su_row class= » »]
[su_column size= »1/2″ center= »no » class= » »]
Avec le cloud personnel, ce sont les services qui viennent aux données.
[/su_column]
[su_column size= »2/2″ center= »no » class= » »]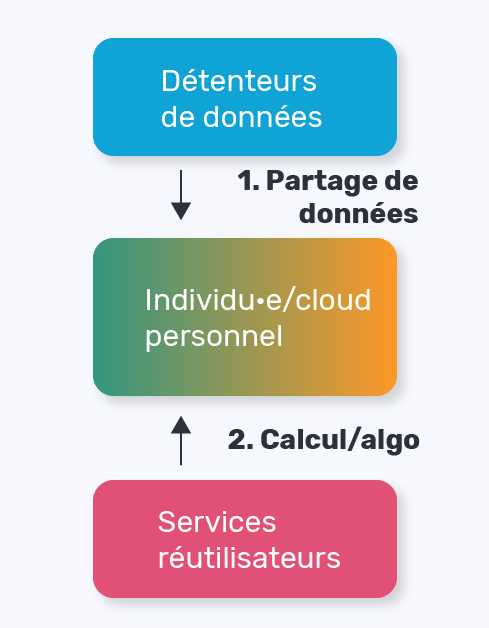 [/su_column]
[/su_column]
[/su_row]
Le cloud personnel repose sur l’idée d’un domicile numérique qui permet aux individus d’agréger leurs données venant de différentes sources sur leur serveur individuel, et non le serveur d’une organisation. L’intérêt de disposer de leur propre serveur repose sur le fait que les services qui vont leur fournir une valeur d’usage sur leurs données vont tourner sur ce serveur (calcul embarqué), sans faire sortir les données. Avec le cloud personnel, ce sont les services qui viennent aux données. Ils peuvent être développés par n’importe qui, sur la base de jeux de données de synthèse. Aucune donnée n’a besoin de sortir de leur domicile numérique et pourtant les individus peuvent tout de même profiter de services et d’applications qui mobilisent et croisent leurs données, disponibles par exemple sur le “Store” du *cloud* personnel ! Les individus ont la maîtrise de leurs données, elles sont stockées sur leurs propres machines, virtuelles, ou en local (ils/elles peuvent faire de l’auto-hébergement).
Le cloud personnel est cependant encore très neuf. L’adoption par les individus mais également par les détenteurs de données peut être un frein. S’ils disposent de nombreux avantages à utiliser une telle plateforme, cela reste un intermédiaire supplémentaire entre eux et leurs clients/usagers, des canaux de transmission et connecteurs à garder à jour, et pour les individus un outil supplémentaire à maîtriser. Pour les réutilisateurs, ceux qui fournissent les services, c’est également un investissement : s’il représente un véritable intérêt en termes de confiance envers les individus – un réutilisateur peut fournir un service sans s’encombrer du rôle de responsable de traitement – les services tiers doivent s’adapter et se coordonner avec cet acteur supplémentaire, à la stratégie indépendante de la leur. Ils doivent s’adapter techniquement à une ou plusieurs plateformes, alors que la plupart développent des services pour des systèmes d’exploitation fournis par les GAFA (IOS-Apple ou Android-Google) ou dans des “écosystèmes” fermés mais de grande taille (Facebook). C’est un ajustement difficile, les plateformes du Self Data débutent et ne dis- posent pas du même volume d’utilisateurs.
Dans une économie numérique où les données sont partagées avec de nombreux services (assistant personnel, application de transports, etc) pour assurer leur fonctionnement, nous mesurons ici tout l’intérêt d’environnements tels que le “cloud personnel” : les croisements de données s’effectuent à l’intérieur d’un espace numérique privé, porté par un tiers de confiance hébergeur. Aujourd’hui, le *cloud* personnel est plutôt centré sur les individus, “un *cloud* personnel = un individu”. Mais il existe des projets de recherche pour faire des choses plus collectives, pour tirer des usages collectifs des données personnelles dans les clouds des individus, en permettant par exemple de faire tourner des algorithmes sur des milliers de clouds, sans en faire sortir les données, pour opérer dans des logiques de Big Data tout en laissant les individus en contrôle de leurs données. De plus, les fonctionnalités de partage entre clouds personnels (pour partager des données entre individus, les mettre en commun, etc) vont en s’améliorant.
Le transfert direct
[su_row class= » »]
[su_column size= »1/2″ center= »no » class= » »]
Contrairement au cloud personnel, ici ce sont les données qui vont aux services.
[/su_column]
[su_column size= »2/2″ center= »no » class= » »]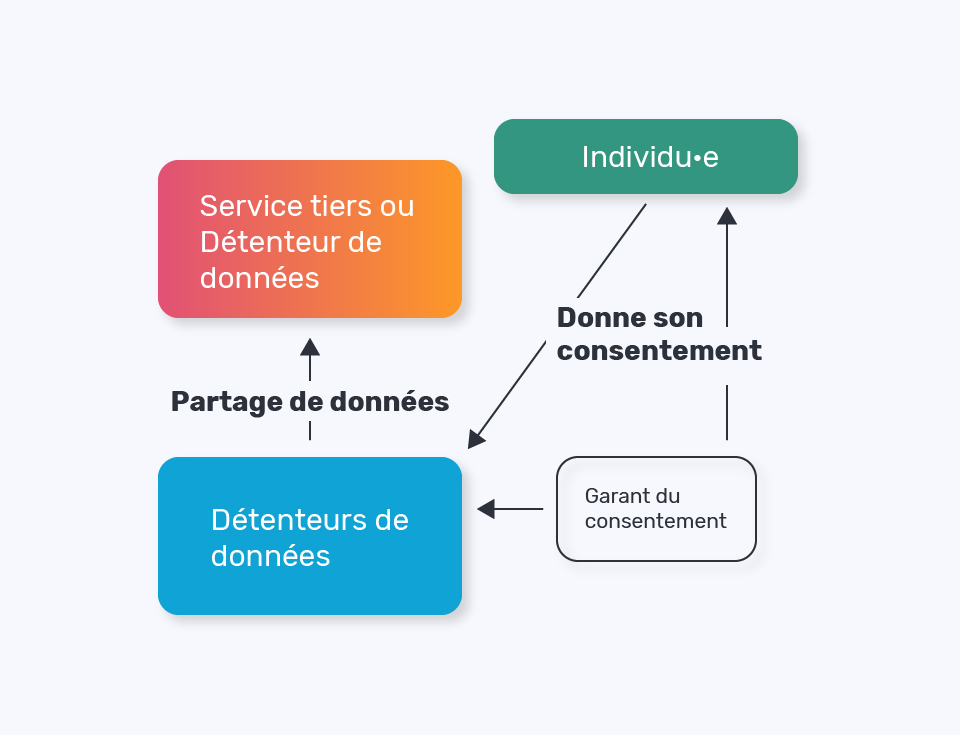 [/su_column]
[/su_column]
[/su_row]
Le transfert direct repose sur un principe clef : le consentement. Le partage de données se fait entre responsables de traitement directement, avec le consentement – révocable – de l’individu, pour lui fournir un service, pour participer à une cause d’intérêt général, à un projet de recherche. Par exemple chez les énergéticiens, avec le projet “Enedis Data Connect” les individus disposant d’un compteur connecté Linky vont pouvoir profiter de services tiers, qui vont aller se connecter, avec leur consente- ment, au système d’information d’Enedis, pour leur fournir une valeur d’usage sur leurs données de consommation. Ce modèle dispose d’un grand avantage : impliquant moins d’acteurs, il est moins complexe à implémenter. Un contrat peut potentiellement être signé entre le détenteur de données et le service réutilisateur pour spécifier les processus, le niveau de protection des données, l’utilisation de l’infrastructure du détenteur pour les récupérer (volume, régularité, …), et nous pouvons imaginer que certains services soient “blacklistés”, qu’ils ne puissent pas se connecter au système du détenteur pour des rai- sons légitimes de sécurité, etc.
Si peu d’organisations mettent en place ce genre de transfert – nous restons sur un modèle qui aujourd’hui n’existe pas vraiment en dehors des acteurs du numérique – c’est probablement celui qui aura vocation à se développer le plus car il ne bouscule pas les codes et correspond au fonctionnement de l’économie numérique actuelle. Il permet de définir clairement les responsabilités de chacun et surtout représente un risque juridique maîtrisé pour les détenteurs et réutilisateurs.
Et pourtant il ne permet pas vraiment à l’individu d’obtenir un 360° sur ses données ou de les maitriser, les services tiers ne vont pas aller se connecter à 1000 API de différentes détenteurs – et signer autant de contrats ! Nous restons donc sur une approche assez sectorielle, avec du côté des réutilisateurs des usages probablement plus limités. De plus, ici l’individu n’est “que” le passage de son consentement, même si c’est fait dans les règles, sa maîtrise reste limitée, il/elle ne voit pas “passer” les données, ne peut pas les réutiliser lui/elle-même et son parcours est morcelé : il/elle doit donner son consentement à deux acteurs minimum, pour chaque service. De plus, contrairement au cloud personnel, ici ce sont les données qui vont aux services, ce qui signifie que les données personnelles sont dupliquées et stockées au sein de chaque service. Cela contribue à la prolifération des données personnelles, et rend vulnérable mécaniquement la vie privé des individus.
Mais un autre acteur peut influer sur cette maîtrise et jouer le rôle de tiers de confiance entre les individus et les organisations (détenteurs, réutilisateurs). Nous les nommons dans le schéma “les garants du transfert”. Ils assurent la sécurité et l’authenticité du partage des données et fournissent – aux organisations et aux individus – un tableau de bord pour gérer les droits sur leurs données (portabilité et donc consentement/partage, droit de suppression, de modification, etc).
La plateforme « tiers de confiance »
[su_row class= » »]
[su_column size= »1/2″ center= »no » class= » »]
La différence essentielle avec le cloud personnel ? Le stockage, ici centralisé sur un serveur, et le traitement des données par des tiers qui se fait en dehors de la plateforme.
[/su_column]
[su_column size= »2/2″ center= »no » class= » »] [/su_column]
[/su_column]
[/su_row]
Ce modèle représente en partie la version 2.0 des coffres-forts numériques : un portail/espace personnel pour récupérer et organiser ses documents et ses données depuis plusieurs sources, mais aussi pour les partager, voire pour profiter de services tiers ou services intégrés à la plateforme. La différence essentielle avec le cloud personnel ? Le stockage, ici centralisé sur un serveur, et le traitement des données par des tiers qui se fait en dehors de la plateforme. Le Dossier Médical Partagé est un exemple de plateforme “tiers de confiance”, bien qu’aujourd’hui il permet surtout d’agréger des documents plutôt que des données et qu’il s’agit surtout de les partager avec des professionnels de santé plutôt que de vraiment les réutiliser avec des services.
La question du tiers de confiance est essentielle : ce modèle est après tout assez proche de celui de Google – sans tiers de confiance le paradigme ne changerait donc pas ! Ici le porteur de la plateforme joue le rôle du garant de la sécurité et du stockage centralisé. La maîtrise de l’outil, des données penche plutôt du côté de l’organisation qui fournit cette plateforme et choisit les services qui pourront l’intégrer – voire comme certaines organisations (qui ne fournissent pas des PIMS) le font déjà (Amazon, Netflix, . . .) pour favoriser leurs propres produits et services… Mais l’individu dispose tout de même d’une vision globale de ses données. Aujourd’hui ce type de plateforme est souvent fourni par de grandes institutions et les usages des données sont plutôt centrées sur des services intégrés et du partage destinés aux particuliers (ex : la plateforme DigiPoste permet de regrouper les documents et données nécessaires pour constituer un dossier immobilier et le partager à une agence, etc).
La coopérative de données
Et si les individus s’organisaient pour gérer en commun leurs données et décider ensemble de leurs usages et partages ? C’est la voix que les – encore peu nombreuses – coopératives de données cherchent à prendre. Sur le modèle 1 individu = 1 voix, un collectif d’individus développe des outils et services (chat, moteur de recherche,…) leur permettant de gérer leurs données de A à Z. Le collectif peut aussi plus simplement décider ensemble de les partager via une plateforme, par exemple pour contribuer à la construction de connaissances communes.
[su_row class= » »]
[su_column size= »1/2″ center= »no » class= » »]
Dans ce modèle les individus reprennent le contrôle de l’usage de leurs données personnelles par d’autres (partage) mais également de l’usage qu’ils/elles vont en faire eux/elles- mêmes (production de services).
[/su_column]
[su_column size= »2/2″ center= »no » class= » »] [/su_column]
[/su_column]
[/su_row]
Dans ce modèle les individus reprennent le contrôle de l’usage de leurs données personnelles par d’autres (partage) mais également de l’usage qu’ils/elles vont en faire eux/elles- mêmes (production de services). Ils peuvent reprendre à leur compte des services open source et indépendants (boîtes mail, chats, . . .) ou développer leurs propres services. Ce modèle est particulièrement utile pour des usages collectifs, où il devient nécessaire de gérer les don- nées en commun, car les données personnelles ont moins d’intérêt isolées par individu. Antonio Casilli et Paola Tubaro affirment dans leur tribune qu’“il n’y a rien de plus collectif qu’une donnée personnelle” et Lionel Maurel (Calimaq) qu’”à la dimension collective des données doit être attaché un pouvoir de décision collectif appartenant irréfragablement et solidairement à la collectivité”. La coopérative de donnée peut- elle offrir un modèle soutenable pour donner vie à ces affirmations ?
Si l’exemple des coopératives permet d’envisager des modèles de gouvernance de nos don- nées différents des schémas classiques, ils ne sont pas exempts de leurs propres limites : le temps à consacrer à la gouvernance d’une coopérative par ses membres (plus elle grandit,
La régie de données / Civic Data Trust
[su_row class= » »]
[su_column size= »1/2″ center= »no » class= » »]
Comme pour le modèle de plateforme, la question de “qui est ce tiers ?” est essentielle.
[/su_column]
[su_column size= »2/2″ center= »no » class= » »]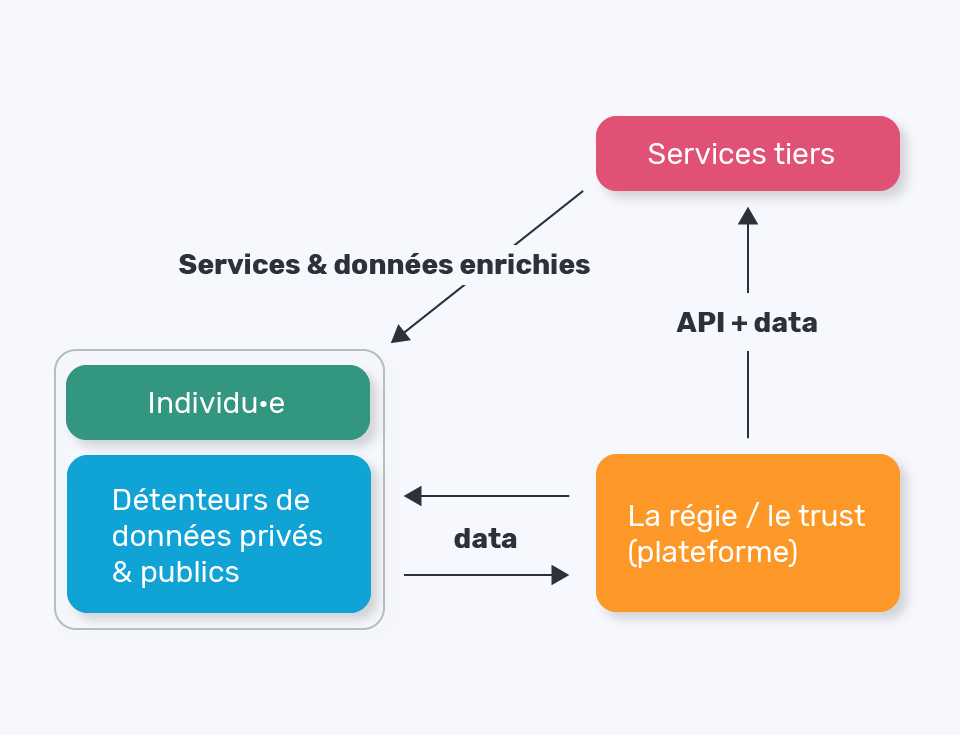 [/su_column]
[/su_column]
[/su_row]
La régie de données, connue dans le monde anglo-saxon comme “(Civic) Data Trust” est selon l’Open Data Institute “une structure légale qui permet une gestion indépendante des données par un tiers de confiance”.
Le régisseur (“trustee”) peut être composé de différents corps, qui représentent les acteurs publics, les acteurs privés et la société civile. Ses règles de gouvernance peuvent être multiples mais doivent permettre d’arriver à un consensus sur l’usage des données personnelles et non personnelles qui lui sont confiées par les individus et les détenteurs de données. Il peut les détenir physiquement, via une véritable plateforme (comme sur notre schéma), ou bien les laisser là où elles sont et devenir
le garant de leur partage – par exemple pour des causes d’intérêt général, pour des politiques publiques, etc – selon les conditions définies par le groupe. Ce modèle permettrait également de dé- passer l’Open Data : les données publiques seules ne permettent pas véritablement l’émergence de nouveaux services, notamment pour l’intérêt général, et le croisement avec les données personnelles pourrait ouvrir de nouveaux usages.
Aujourd’hui, la plupart des travaux autour de ce modèle portent peu sur la question des données personnelles et de la place de l’individu. Dans les faits, les données personnelles sont traitées de manière périphérique dans les projets de plateformes de données territoriales, de régie, de civic data trust. Mais certains commencent à s’y intéresser, y voyant une manière de créer de la confiance via un ou plusieurs tiers dans une ville numérique saturée par les données. On l’aura compris, comme pour le modèle de plateforme, la question de “qui est ce tiers ?” est essentielle. Après tout, à Toronto, Google se propose de monter un “civic data trust” ce qui a rapidement soulevé des questions comme “Google sera-t-il celui qui choisira les régisseurs qui auront le droit de se mettre autour de la table, et celui qui définira les règles pour se mettre d’accord ?”. Certains commencent à proposer des alternatives comme de confier le trust à la Bibliothèque Nationale de Toronto. Sean McDonald, conclut lui qu’il “est tout aussi facile de construire
plusieurs civic data trust qu’un seul, une ville devrait donc les organiser selon les cas d’usages, les groupes thématiques ou les besoins publics. (…) il est bien plus logique de les traiter comme des unités plus petites et plus agiles qu’une seule grande régie de gouvernance”. Dans tous les cas, pour fonctionner, ce modèle demandera, au même titre que les précédents, que les détenteurs de données acceptent de partager les données qu’ils détiennent, et pour rester dans l’esprit Self Data, que les individus ne soient pas des simples contributeurs à la régie mais détiennent un réel pouvoir dans sa gouvernance pour définir les usages à venir.